

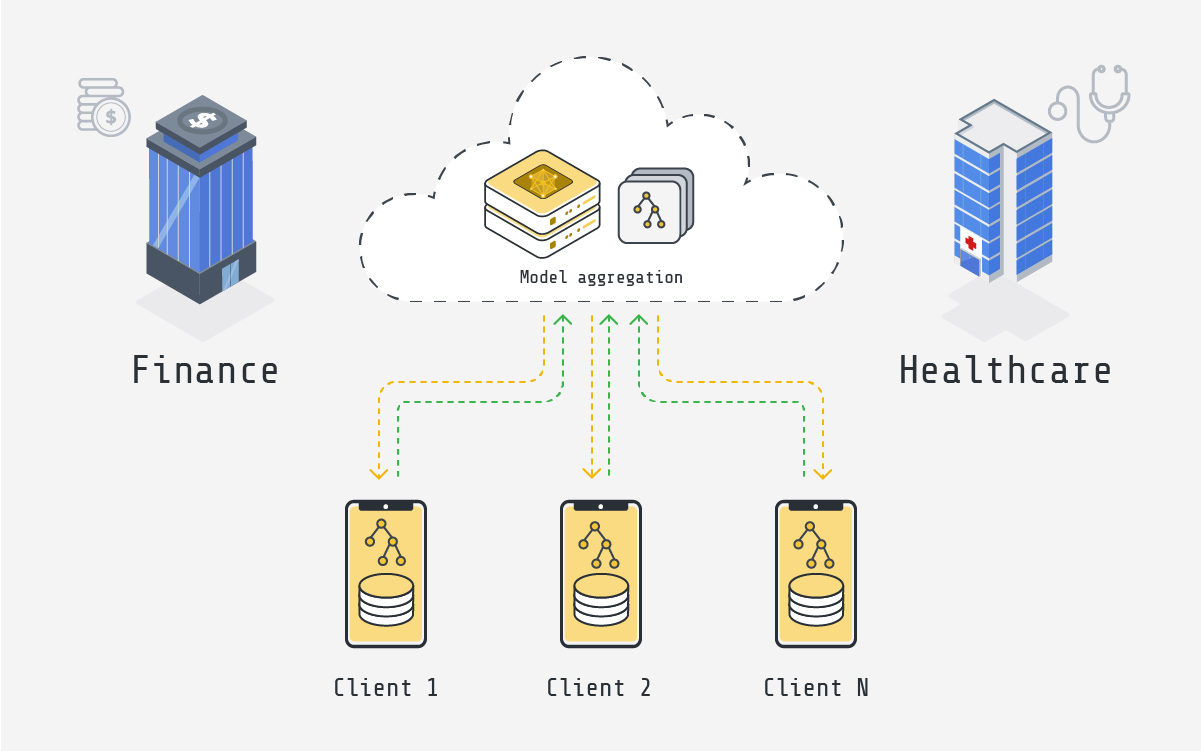
Federated XGBoost
EXtreme Gradient Boosting (XGBoost) is a highly efficient and flexible gradient boosting framework. It's widely used for machine learning tasks, particularly in structured or tabular data. The combination with federated learning allows XGBoost models being trained on distributed datasets without compromising data privacy.
This is particularly relevant in scenarios where data privacy is crucial, such as in healthcare or finance, where data might not be allowed to leave the premises due to regulatory requirements.
Healthcare application
Hospitals and healthcare institutions can collaborate to improve disease prediction models without sharing patient data. Federated XGBoost can help in creating more personalized treatment plans by learning from a wide array of patient data across different regions or institutions, again without compromising patient privacy.
Finance application
Banks and financial institutions can collaborate to improve credit scoring models or fraud detection system. By training on a diverse range of financial data from different banks, the model can more accurately assess creditworthiness or fraudulent patterns and behaviors, while keeping their transactional data private.
These applications demonstrate how federated XGBoost can be a game-changer in industries where data sensitivity is a key concern. By enabling collaborative model training without compromising data privacy, it opens up new possibilities for leveraging big data in ways that were previously challenging due to privacy concerns.
Federated XGBoost with Flower
Along with the previous XGBoost quickstart example, we add plenty of new features for the comprehensive example. This positions Flower as having the industry-leading implementation of federated XGBoost. 🎉
Two training strategies
We now provide two training strategies, bagging and cyclic training.
-
Bagging aggregation. Bagging (bootstrap) aggregation, an ensemble meta-algorithm in machine learning, is employed to improve the stability and accuracy of machine learning algorithms. In this context, we utilize this algorithm specifically for optimizing XGBoost trees. See details in the previous blogpost.
-
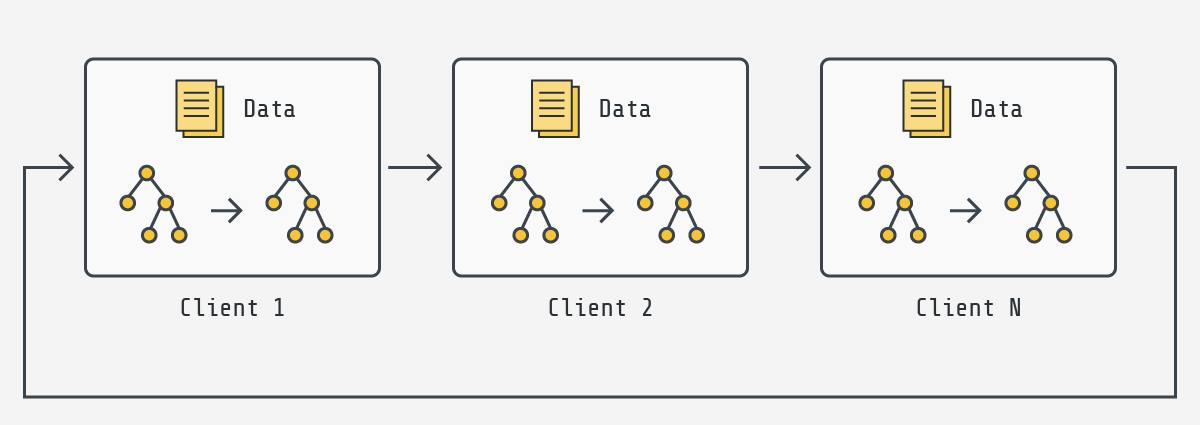
Cyclic training. As shown in the figure below, cyclic XGBoost training performs FL in a client-by-client fashion. Instead of aggregating multiple clients, there is only one single client participating in the training per round in the cyclic training scenario. The trained local XGBoost trees will be passed to the next client as an initialised model for next round's boosting.
Two ways of running the example
You can run this example in two ways: independent client/server setup or Flower Simulation setup.
-
Independent client/server setup. In this setup, we manually launch the server, and then several clients that connect to it. This is ideal for deployments on different machines.
-
Flower Simulation setup. Here we use the simulation capabilities of Flower to simulate federated XGBoost training on either a single machine or a cluster of machines. This makes it easy to simulate large client cohorts in a resource-aware manner. You can read more about how Flower Simulation works in the Documentation.
Expected experimental results
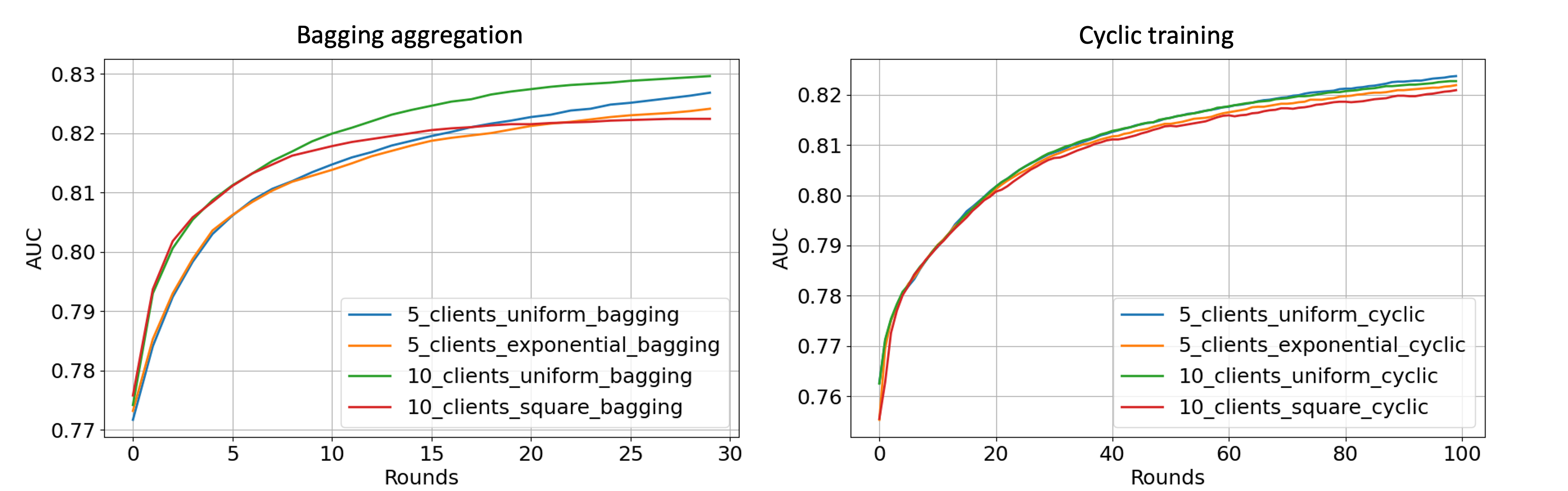
The left figure shows the centralized tested AUC performance over FL rounds with bagging strategy on 4 experimental settings. It is evident that all settings consistently achieve a stable performance enhancement over the course of multiple FL rounds. The right figure shows the cyclic training results on a centralized test set. The models with cyclic training require more rounds to converge because only a single client participates in the training per round.
The complete example can be found on GitHub (XGBoost comprehensive example). There are several new features designed to support a variety of experimental settings, which are not presented here. Please check out the code and tutorial for further exploration of federated XGBoost!