Federated Learning with Personalization Layers#

Note: If you use this baseline in your work, please remember to cite the original authors of the paper as well as the Flower paper.
Paper: arxiv.org/abs/1912.00818
Authors: Manoj Ghuhan Arivazhagan, Vinay Aggarwal, Aaditya Kumar Singh, and Sunav Choudhary
Abstract: The emerging paradigm of federated learning strives to enable collaborative training of machine learning models on the network edge without centrally aggregating raw data and hence, improving data privacy. This sharply deviates from traditional machine learning and necessitates design of algorithms robust to various sources of heterogeneity. Specifically, statistical heterogeneity of data across user devices can severely degrade performance of standard federated averaging for traditional machine learning applications like personalization with deep learning. This paper proposes FedPer, a base + personalization layer approach for federated training of deep feed forward neural networks, which can combat the ill-effects of statistical heterogeneity. We demonstrate effectiveness of FedPer for non-identical data partitions of CIFAR datasets and on a personalized image aesthetics dataset from Flickr.
About this baseline#
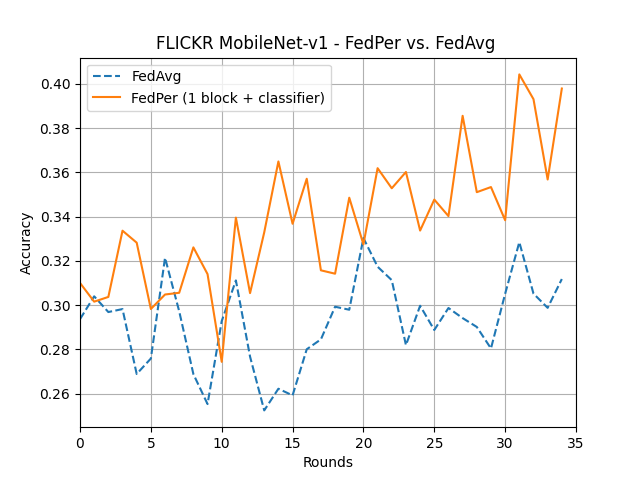
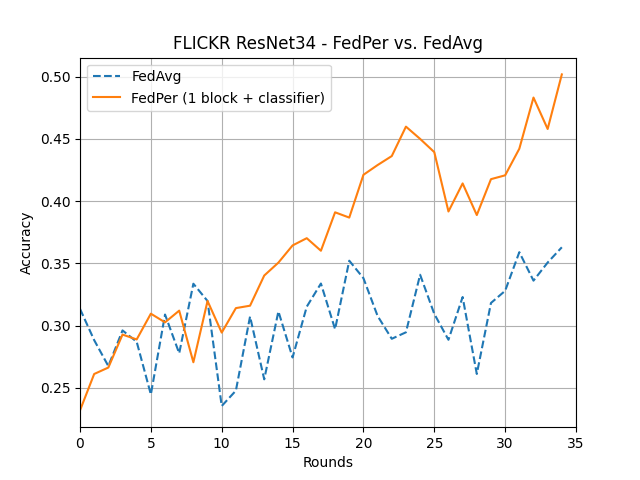
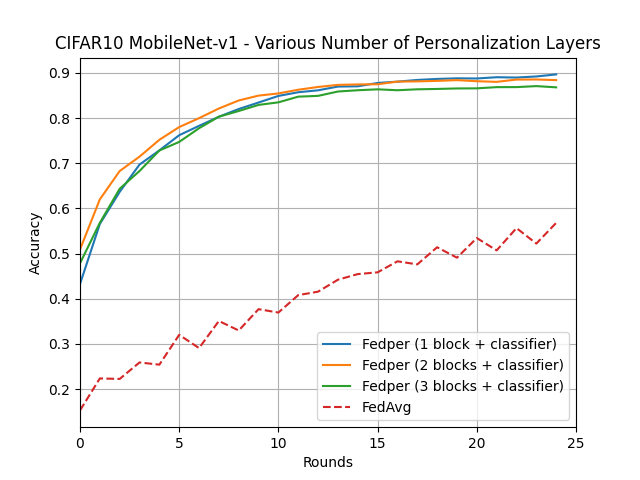
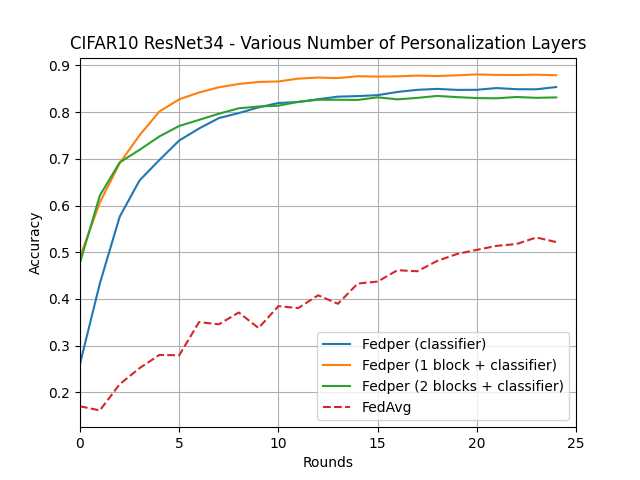
What’s implemented: The code in this directory replicates the experiments in Federated Learning with Personalization Layers (Arivazhagan et al., 2019) for CIFAR10 and FLICKR-AES datasets, which proposed the FedPer model. Specifically, it replicates the results found in figures 2, 4, 7, and 8 in their paper. Note that there is typo in the caption of Figure 4 in the article, it should be CIFAR10 and not CIFAR100.
Datasets: CIFAR10 from PyTorch’s Torchvision and FLICKR-AES. FLICKR-AES was proposed as dataset in Personalized Image Aesthetics (Ren et al., 2017) and can be downloaded using a link provided on their GitHub. One must first download FLICKR-AES-001.zip (5.76GB), extract all inside and place in baseline/FedPer/datasets. To this location, also download the other 2 related files: (1) FLICKR-AES_image_labeled_by_each_worker.csv, and (2) FLICKR-AES_image_score.txt. Images are also scaled to 224x224 for both datasets. This is not explicitly stated in the paper but seems to be boosting performance. Also, for FLICKR dataset, it is stated in the paper that they use data from clients with more than 60 and less than 290 rated images. This amounts to circa 60 clients and we randomly select 30 out of these (as in paper). Therefore, the results might differ somewhat but only slightly. Since the pre-processing steps in the paper are somewhat obscure, the metric values in the plots below may differ slightly, but not the overall results and findings.
# These steps are not needed if you are only interested in CIFAR-10
# Create the `datasets` directory if it doesn't exist already
mkdir datasets
# move/copy the downloaded FLICKR-AES-001.zip file to `datasets/`
# unzip dataset to a directory named `flickr`
cd datasets
unzip FLICKR-AES-001.zip -d flickr
# then move the .csv files inside flickr
mv FLICKR-AES_image_labeled_by_each_worker.csv flickr
mv FLICKR-AES_image_score.txt flickr
Hardware Setup: Experiments have been carried out on GPU. 2 different computers managed to run experiments:
GeForce RTX 3080 16GB
GeForce RTX 4090 24GB
It’s worth mentioning that GPU memory for each client is ~7.5GB. When training on powerful GPUs, one can reduce ratio of GPU needed for each client in the configuration setting to e.g. num_gpus to 0.33.
NOTE: One experiment carried out using 1 GPU (RTX 4090) takes somehwere between 1-3h depending on dataset and model. Running ResNet34 compared to MobileNet-v1 takes approximately 10-15% longer.
Contributors: William Lindskog
Experimental Setup#
Task: Image Classification
Model: This directory implements 2 models:
ResNet34 which can be imported directly (after having installed the packages) from PyTorch, using `from torchvision.models import resnet34
MobileNet-v1
Please see how models are implemented using a so called model_manager and model_split class since FedPer uses head and base layers in a neural network. These classes are defined in the models.py file and thereafter called when building new models in the directory /implemented_models. Please, extend and add new models as you wish.
Dataset: CIFAR10, FLICKR-AES. CIFAR10 will be partitioned based on number of classes for data that each client shall receive e.g. 4 allocated classes could be [1, 3, 5, 9]. FLICKR-AES is an unbalanced dataset, so there we only apply random sampling.
Training Hyperparameters: The hyperparameters can be found in conf/base.yaml file which is the configuration file for the main script.
Description |
Default Value |
|---|---|
num_clients |
10 |
clients per round |
10 |
number of rounds |
50 |
client resources |
{‘num_cpus’: 4, ‘num_gpus’: 1 } |
learning_rate |
0.01 |
batch_size |
128 |
optimizer |
SGD |
algorithm |
fedavg |
Stateful Clients: In this Baseline (FedPer), we must store the state of the local client head while aggregation of body parameters happen at the server. Flower is currently making this possible but for the time being, we reside to storing client head state in a folder called client_states. We store the values after each fit and evaluate function carried out on each client, and call for the state before executing these functions. Moreover, the state of a unique client is accessed using the client ID.
NOTE: This is a work-around so that the local head parameters are not reset before each fit and evaluate. Nevertheless, it can come to change with future releases.
Environment Setup#
To construct the Python environment follow these steps:
# Set Python 3.10
pyenv local 3.10.6
# Tell poetry to use python 3.10
poetry env use 3.10.6
# Install the base Poetry environment
poetry install
# Activate the environment
poetry shell
Running the Experiments#
python -m fedper.main # this will run using the default settings in the `conf/base.yaml`
# When running models for flickr dataset, it is important to keep batch size at 4 or lower since some clients (for reproducing experiment) will have very few examples of one class
While the config files contain a large number of settings, the ones below are the main ones you’d likely want to modify to .
algorithm: fedavg, fedper # these are currently supported
server_device: 'cuda:0', 'cpu'
dataset.name: 'cifar10', 'flickr'
num_classes: 10, 5 # respectively
dataset.num_classes: 4, 8, 10 # for non-iid split assigning n num_classes to each client (these numbers for CIFAR10 experiments)
model_name: mobile, resnet
To run multiple runs, one can also reside to HYDRA’s multirun option.
# for CIFAR10
python -m fedper.main --multirun --config_name cifar10 dataset.num_classes=4,8,10 model_name=resnet,mobile algorithm=fedper,fedavg model.num_head_layers=2,3
# to repeat each run 5 times, one can also add
python -m fedper.main --multirun --config_name cifar10 dataset.num_classes=4,8,10 model_name=resnet,mobile algorithm=fedper,fedavg model.num_head_layers=2,3 '+repeat_num=range(5)'
Expected Results#
To reproduce figures make fedper/run_figures.sh executable and run it. By default all experiments will be run:
# Make fedper/run_figures.sh executable
chmod u+x fedper/run_figures.sh
# Run the script
bash fedper/run_figures.sh
Having run the run_figures.sh, the expected results should look something like this:
MobileNet-v1 and ResNet-34 on CIFAR10
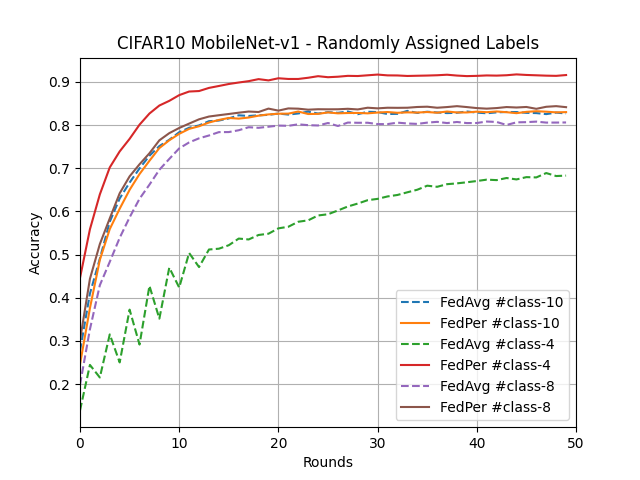
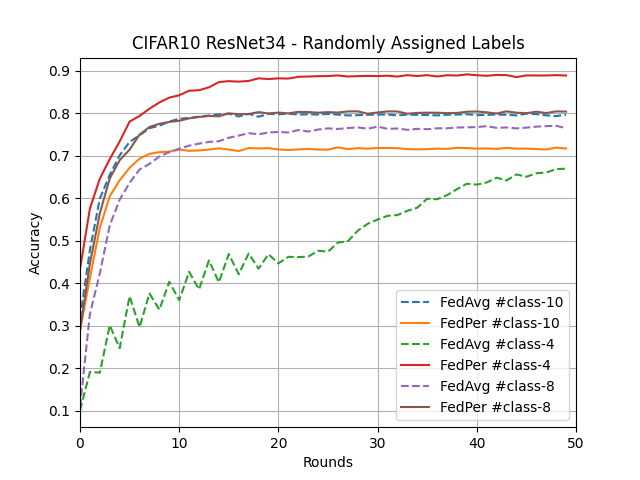
MobileNet-v1 and ResNet-34 on CIFAR10 using varying size of head
MobileNet-v1 and ResNet-34 on FLICKR-AES