Qu’est-ce que l’apprentissage fédéré ?#
Bienvenue au tutoriel sur l’apprentissage fédéré de la fleur !
In this tutorial, you will learn what federated learning is, build your first system in Flower, and gradually extend it. If you work through all parts of the tutorial, you will be able to build advanced federated learning systems that approach the current state of the art in the field.
🧑🏫 Ce tutoriel part de zéro et n’attend aucune familiarité avec l’apprentissage fédéré. Seule une compréhension de base de la science des données et de la programmation Python est supposée.
Star Flower on GitHub ⭐️ and join the open-source Flower community on Slack to connect, ask questions, and get help: Join Slack 🌼 We’d love to hear from you in the
#introductionschannel! And if anything is unclear, head over to the#questionschannel.
Let’s get started!
Apprentissage automatique classique#
Avant de commencer à discuter de l’apprentissage fédéré, récapitulons rapidement la façon dont la plupart des apprentissages automatiques fonctionnent aujourd’hui.
Dans l’apprentissage automatique, nous avons un modèle et des données. Le modèle peut être un réseau neuronal (comme illustré ici), ou quelque chose d’autre, comme la régression linéaire classique.

Nous entraînons le modèle en utilisant les données pour effectuer une tâche utile. Une tâche peut consister à détecter des objets dans des images, à transcrire un enregistrement audio ou à jouer à un jeu comme le Go.

Now, in practice, the training data we work with doesn’t originate on the machine we train the model on. It gets created somewhere else.
It originates on a smartphone by the user interacting with an app, a car collecting sensor data, a laptop receiving input via the keyboard, or a smart speaker listening to someone trying to sing a song.

Il est également important de mentionner que cet « ailleurs » n’est généralement pas un seul endroit, mais plusieurs. Il peut s’agir de plusieurs appareils fonctionnant tous avec la même application. Mais il peut également s’agir de plusieurs organisations, qui génèrent toutes des données pour la même tâche.
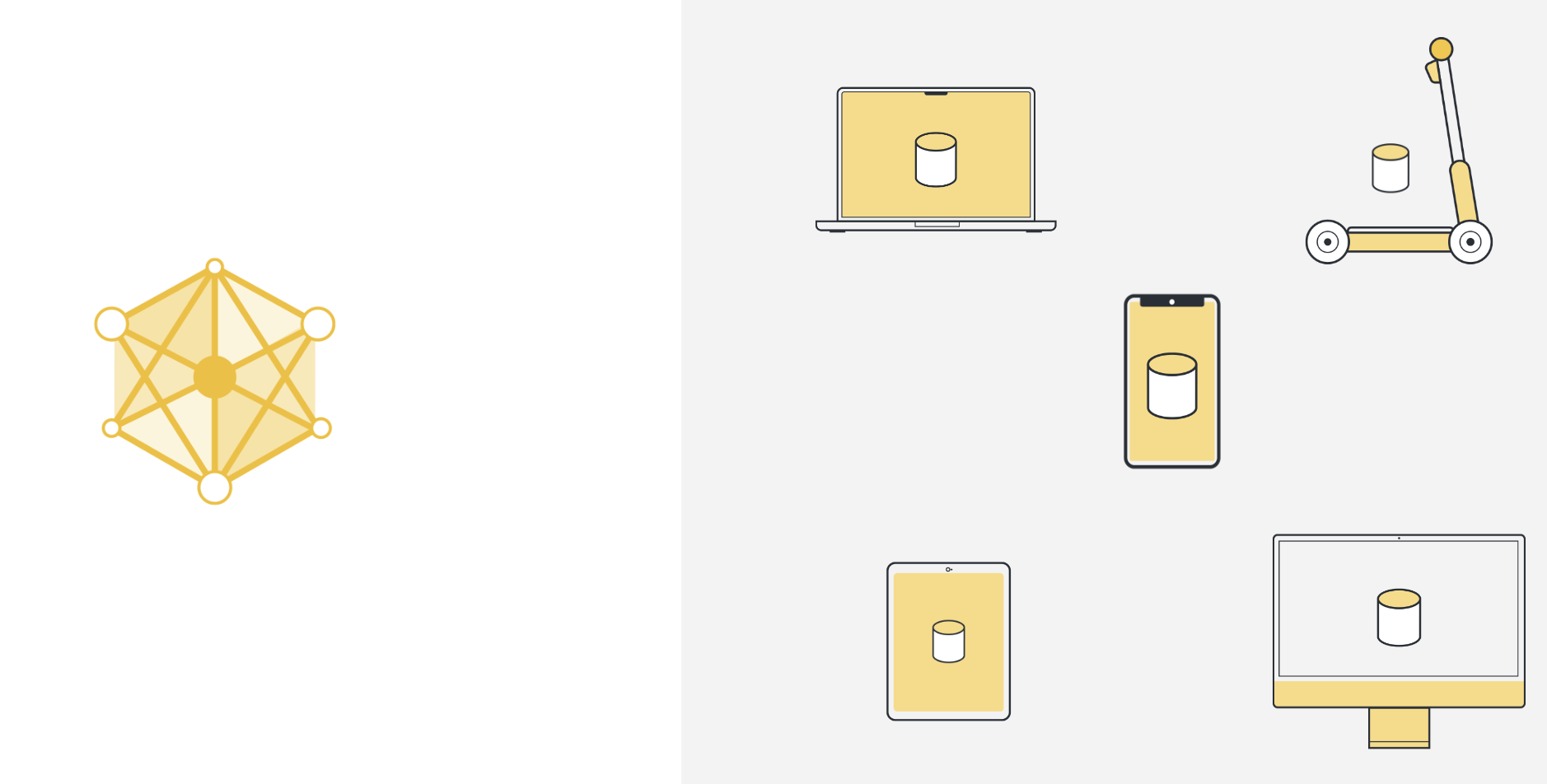
Ainsi, pour utiliser l’apprentissage automatique, ou tout autre type d’analyse de données, l’approche utilisée par le passé consistait à collecter toutes les données sur un serveur central. Ce serveur peut se trouver quelque part dans un centre de données, ou quelque part dans le cloud.
Once all the data is collected in one place, we can finally use machine learning algorithms to train our model on the data. This is the machine learning approach that we’ve basically always relied on.
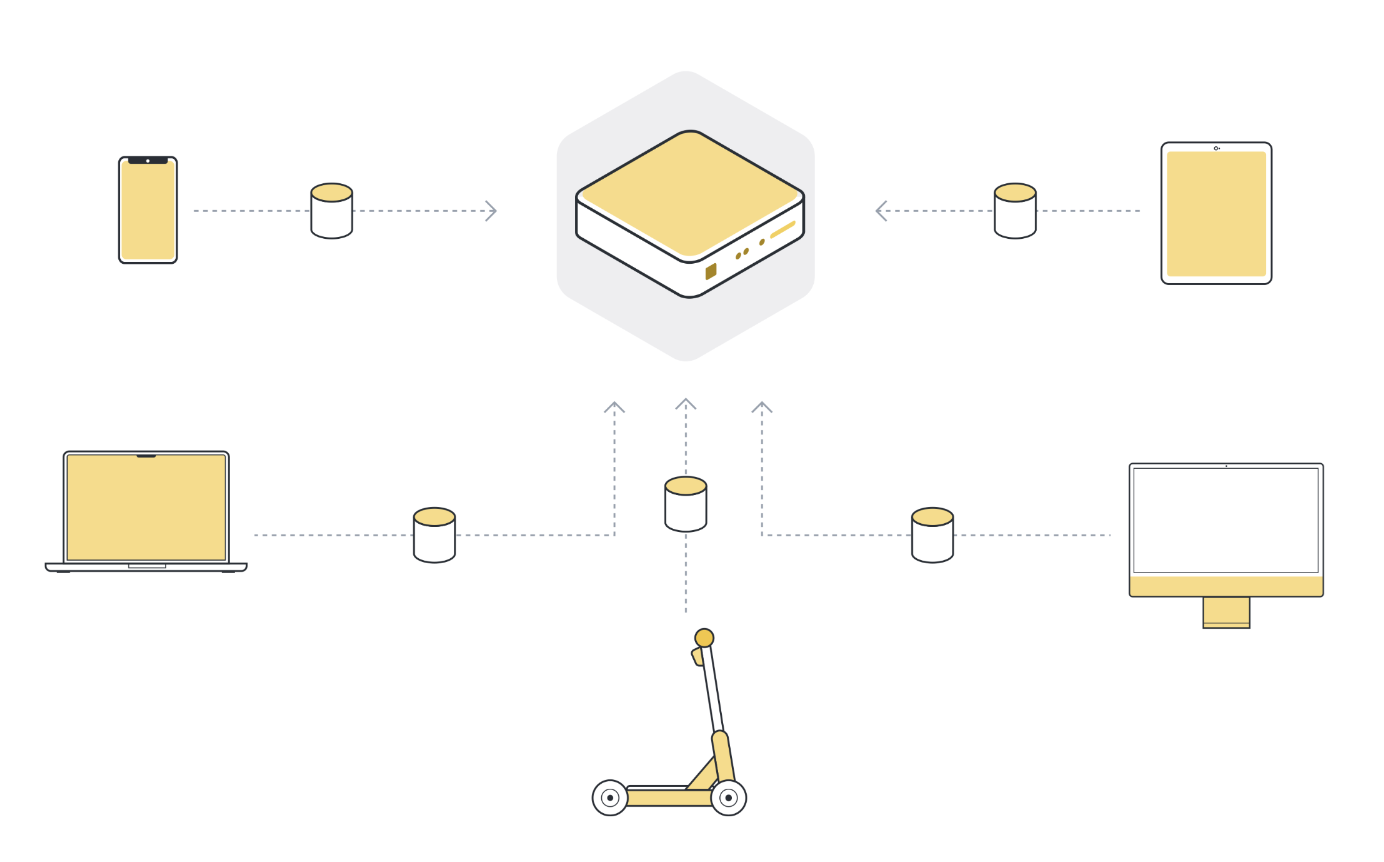
Les défis de l’apprentissage automatique classique#
L’approche classique de l’apprentissage automatique que nous venons de voir peut être utilisée dans certains cas. Parmi les grands exemples, on peut citer la catégorisation des photos de vacances, ou l’analyse du trafic web. Des cas, où toutes les données sont naturellement disponibles sur un serveur centralisé.

Mais cette approche ne peut pas être utilisée dans de nombreux autres cas : lorsque les données ne sont pas disponibles sur un serveur centralisé, ou lorsque les données disponibles sur un serveur ne sont pas suffisantes pour former un bon modèle.
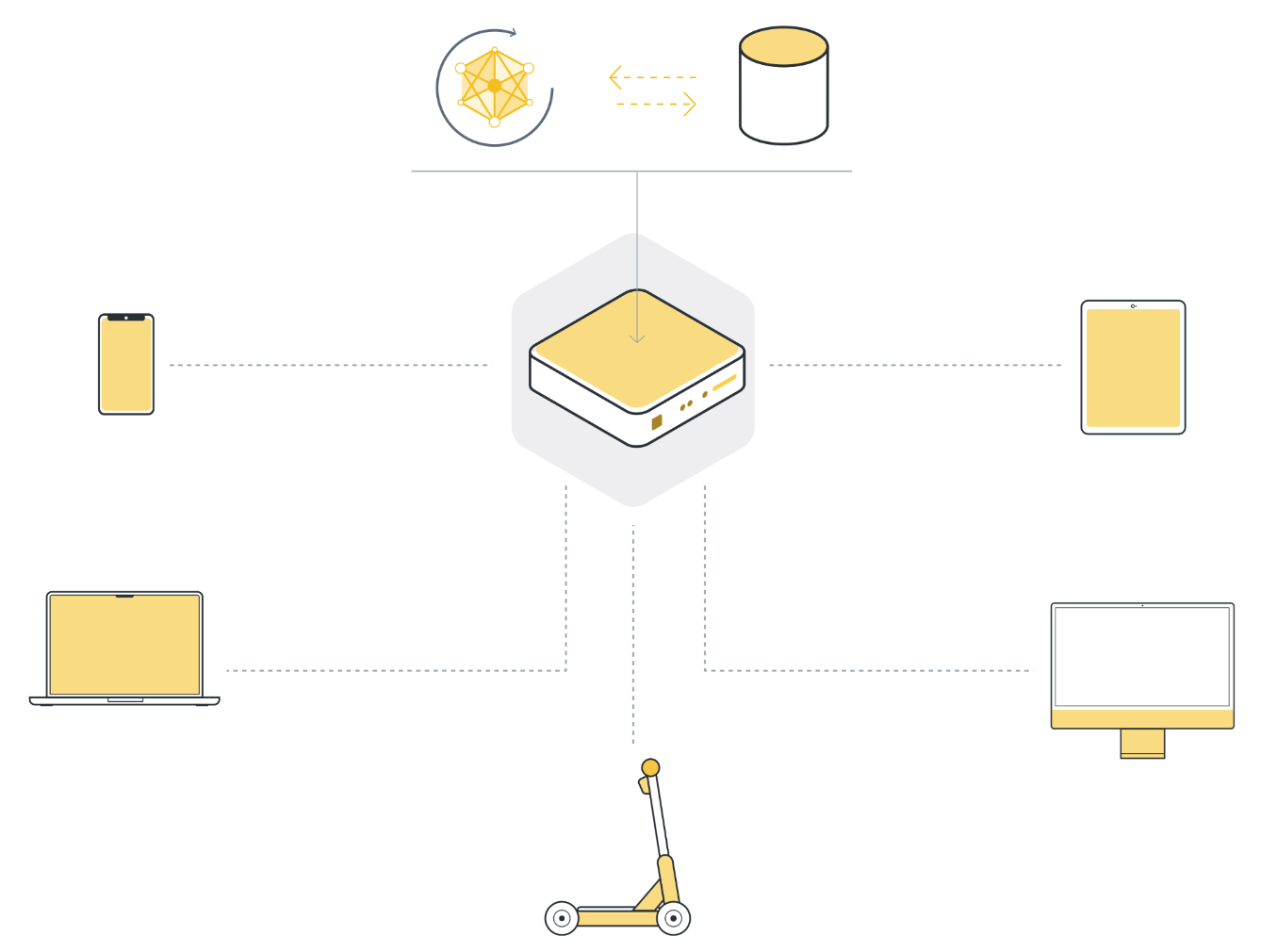
There are many reasons why the classic centralized machine learning approach does not work for a large number of highly important real-world use cases. Those reasons include:
Regulations: GDPR (Europe), CCPA (California), PIPEDA (Canada), LGPD (Brazil), PDPL (Argentina), KVKK (Turkey), POPI (South Africa), FSS (Russia), CDPR (China), PDPB (India), PIPA (Korea), APPI (Japan), PDP (Indonesia), PDPA (Singapore), APP (Australia), and other regulations protect sensitive data from being moved. In fact, those regulations sometimes even prevent single organizations from combining their own users” data for artificial intelligence training because those users live in different parts of the world, and their data is governed by different data protection regulations.
Préférence de l’utilisateur : En plus de la réglementation, il existe des cas d’utilisation où les utilisateurs s’attendent tout simplement à ce qu’aucune donnée ne quitte leur appareil, jamais. Si tu tapes tes mots de passe et tes informations de carte de crédit sur le clavier numérique de ton téléphone, tu ne t’attends pas à ce que ces mots de passe finissent sur le serveur de l’entreprise qui a développé ce clavier, n’est-ce pas ? En fait, ce cas d’utilisation est la raison pour laquelle l’apprentissage fédéré a été inventé en premier lieu.
Data volume: Some sensors, like cameras, produce such a high data volume that it is neither feasible nor economic to collect all the data (due to, for example, bandwidth or communication efficiency). Think about a national rail service with hundreds of train stations across the country. If each of these train stations is outfitted with a number of security cameras, the volume of raw on-device data they produce requires incredibly powerful and exceedingly expensive infrastructure to process and store. And most of the data isn’t even useful.
Voici quelques exemples où l’apprentissage automatique centralisé ne fonctionne pas :
Sensitive healthcare records from multiple hospitals to train cancer detection models
Informations financières provenant de différentes organisations pour détecter les fraudes financières
Les données de localisation de ta voiture électrique pour mieux prédire l’autonomie
Messages cryptés de bout en bout pour former de meilleurs modèles d’autocomplétion
The popularity of privacy-enhancing systems like the Brave browser or the Signal messenger shows that users care about privacy. In fact, they choose the privacy-enhancing version over other alternatives, if such an alternative exists. But what can we do to apply machine learning and data science to these cases to utilize private data? After all, these are all areas that would benefit significantly from recent advances in AI.
Apprentissage fédéré#
L’apprentissage fédéré inverse simplement cette approche. Il permet l’apprentissage automatique sur des données distribuées en déplaçant la formation vers les données, au lieu de déplacer les données vers la formation. Voici l’explication en une seule phrase :
Apprentissage automatique central : déplace les données vers le calcul
Apprentissage (machine) fédéré : déplacer le calcul vers les données
Ce faisant, il nous permet d’utiliser l’apprentissage automatique (et d’autres approches de science des données) dans des domaines où cela n’était pas possible auparavant. Nous pouvons désormais former d’excellents modèles d’IA médicale en permettant à différents hôpitaux de travailler ensemble. Nous pouvons résoudre les fraudes financières en formant des modèles d’IA sur les données de différentes institutions financières. Nous pouvons créer de nouvelles applications d’amélioration de la confidentialité (telles que la messagerie sécurisée) qui ont une meilleure IA intégrée que leurs alternatives d’amélioration de la confidentialité. Et ce ne sont là que quelques exemples qui me viennent à l’esprit. Au fur et à mesure que nous déployons l’apprentissage fédéré, nous découvrons de plus en plus de domaines qui peuvent soudainement être réinventés parce qu’ils ont maintenant accès à de vastes quantités de données auparavant inaccessibles.
Comment fonctionne l’apprentissage fédéré ? Commençons par une explication intuitive.
L’apprentissage fédéré en cinq étapes#
Étape 0 : Initialisation du modèle global#
Nous commençons par initialiser le modèle sur le serveur. C’est exactement la même chose dans l’apprentissage centralisé classique : nous initialisons les paramètres du modèle, soit de façon aléatoire, soit à partir d’un point de contrôle précédemment sauvegardé.
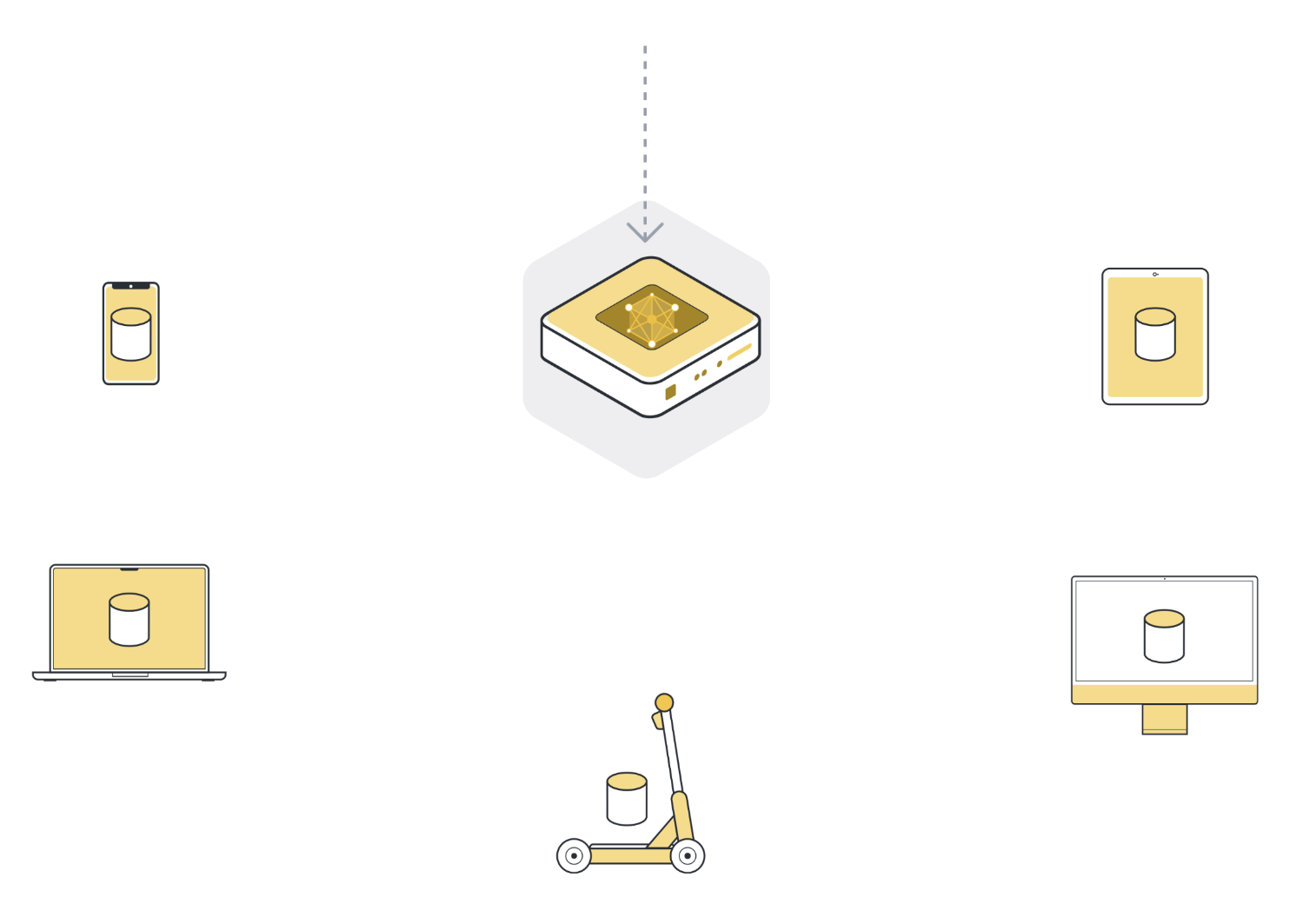
Étape 1 : envoyer le modèle à un certain nombre d’organisations/appareils connectés (nœuds clients)#
Next, we send the parameters of the global model to the connected client nodes (think: edge devices like smartphones or servers belonging to organizations). This is to ensure that each participating node starts their local training using the same model parameters. We often use only a few of the connected nodes instead of all nodes. The reason for this is that selecting more and more client nodes has diminishing returns.
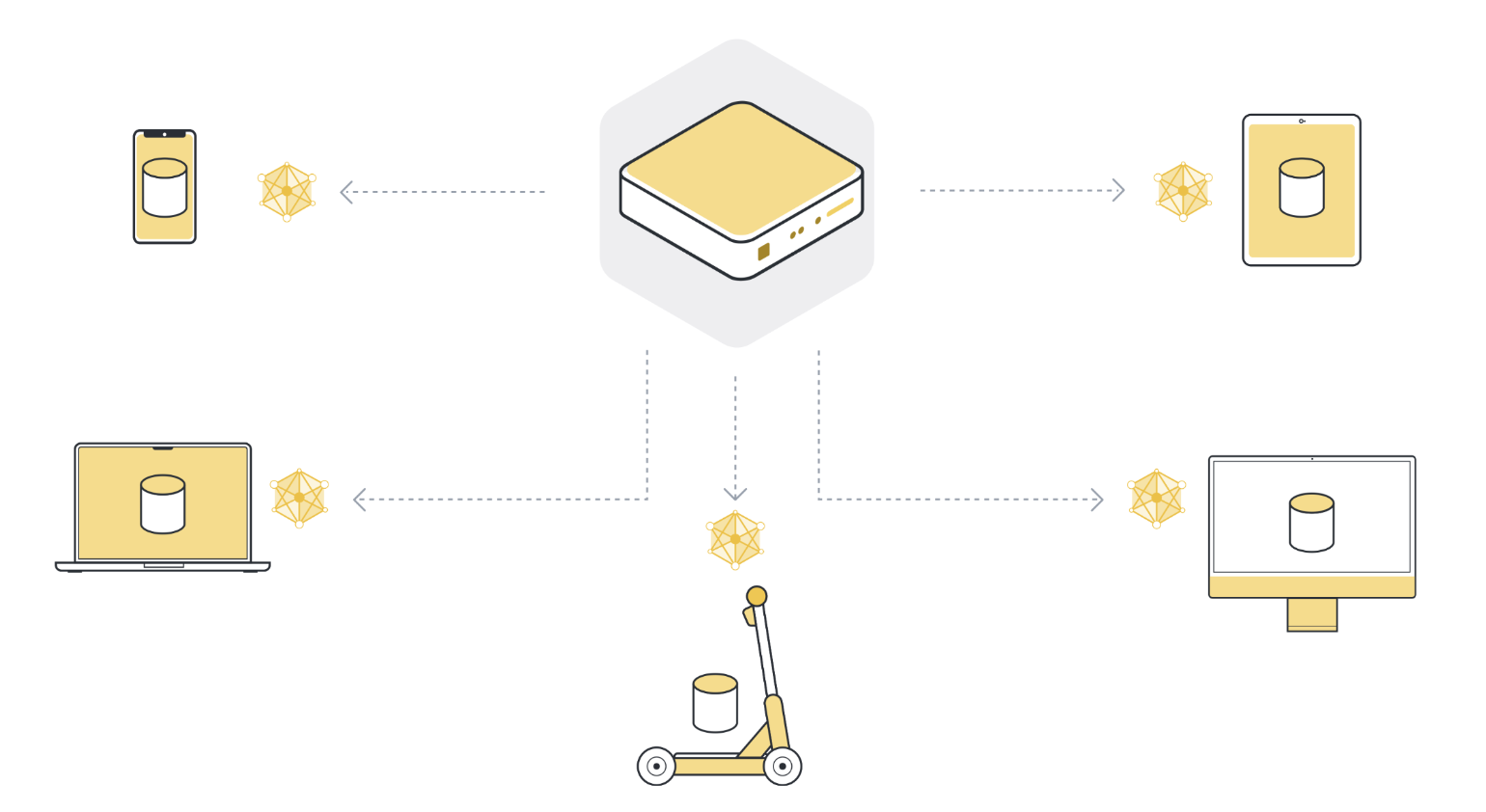
Étape 2 : Entraîne le modèle localement sur les données de chaque organisation/appareil (nœud client)#
Maintenant que tous les nœuds clients (sélectionnés) disposent de la dernière version des paramètres du modèle global, ils commencent l’entraînement local. Ils utilisent leur propre ensemble de données locales pour entraîner leur propre modèle local. Ils n’entraînent pas le modèle jusqu’à la convergence totale, mais ils ne s’entraînent que pendant un petit moment. Il peut s’agir d’une seule époque sur les données locales, ou même de quelques étapes (mini-batchs).
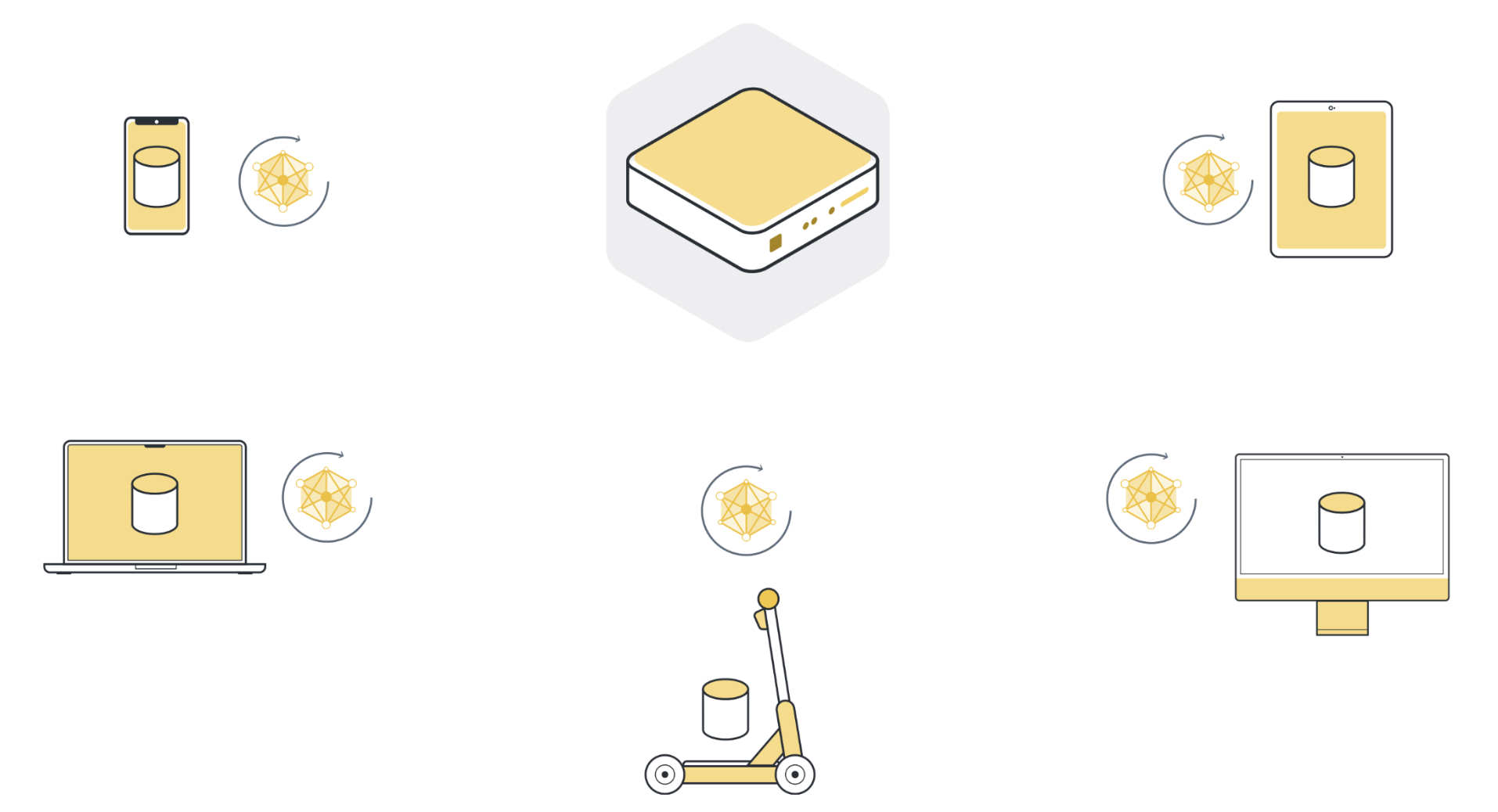
Étape 3 : Renvoyer les mises à jour du modèle au serveur#
Après l’entraînement local, chaque nœud client possède une version légèrement différente des paramètres du modèle qu’il a reçus à l’origine. Les paramètres sont tous différents parce que chaque nœud client a des exemples différents dans son ensemble de données local. Les nœuds clients renvoient ensuite ces mises à jour du modèle au serveur. Les mises à jour du modèle qu’ils envoient peuvent être soit les paramètres complets du modèle, soit seulement les gradients qui ont été accumulés au cours de l’entraînement local.
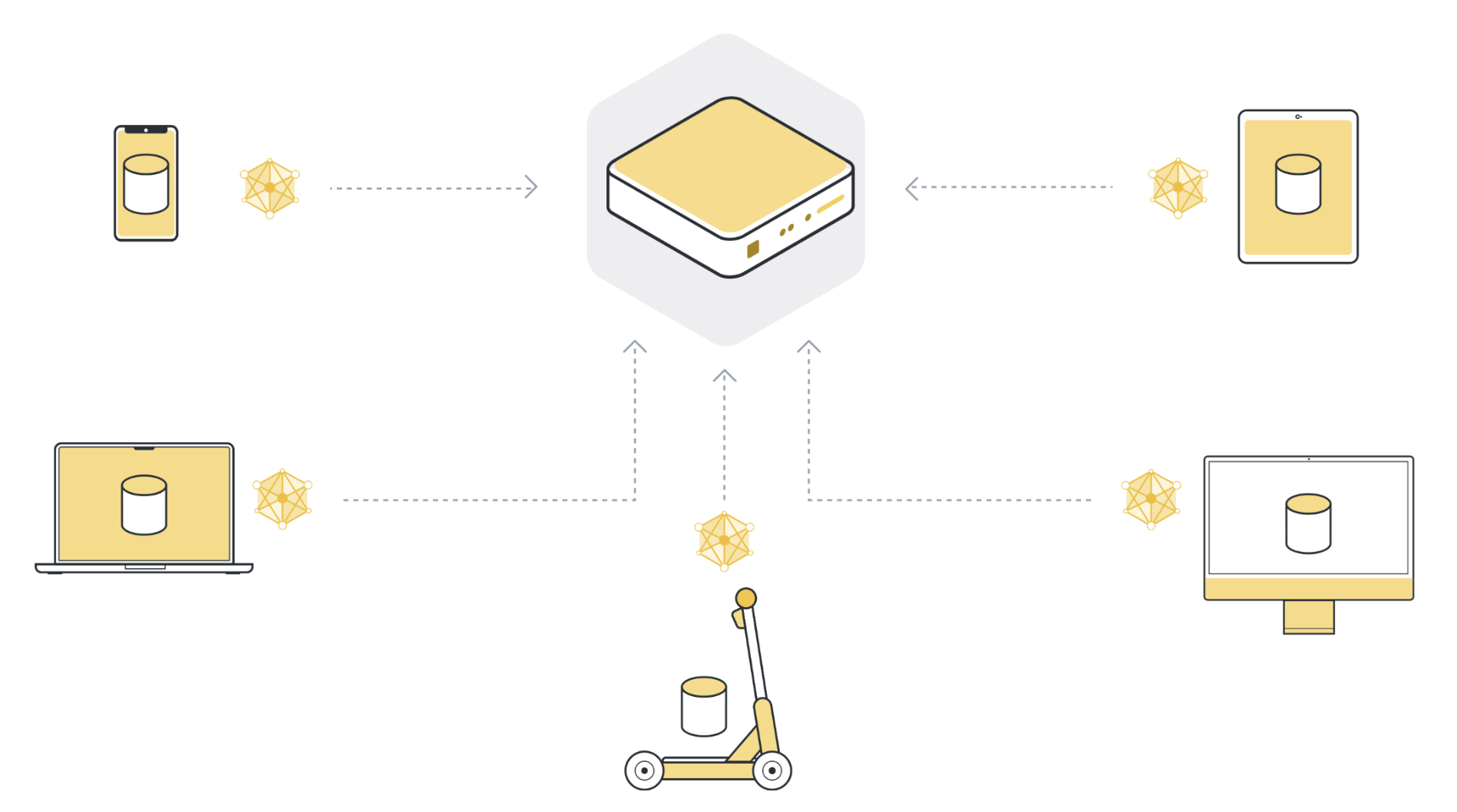
Étape 4 : Agréger les mises à jour des modèles dans un nouveau modèle global#
Le serveur reçoit les mises à jour du modèle des nœuds clients sélectionnés. S’il a sélectionné 100 nœuds clients, il dispose maintenant de 100 versions légèrement différentes du modèle global original, chacune ayant été formée sur les données locales d’un client. Mais ne voulions-nous pas avoir un seul modèle qui contienne les apprentissages des données de l’ensemble des 100 nœuds clients ?
In order to get one single model, we have to combine all the model updates we received from the client nodes. This process is called aggregation, and there are many different ways to do it. The most basic way to do it is called Federated Averaging (McMahan et al., 2016), often abbreviated as FedAvg. FedAvg takes the 100 model updates and, as the name suggests, averages them. To be more precise, it takes the weighted average of the model updates, weighted by the number of examples each client used for training. The weighting is important to make sure that each data example has the same « influence » on the resulting global model. If one client has 10 examples, and another client has 100 examples, then - without weighting - each of the 10 examples would influence the global model ten times as much as each of the 100 examples.
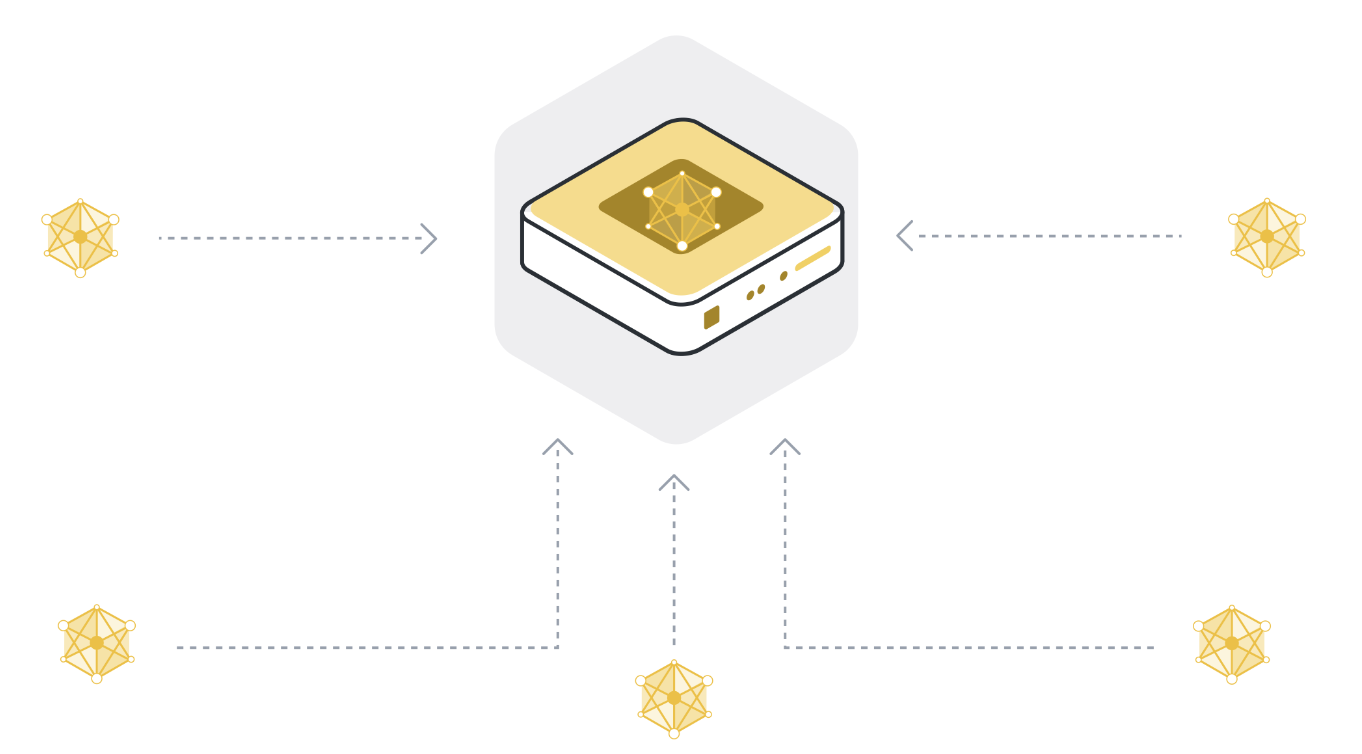
Étape 5 : répète les étapes 1 à 4 jusqu’à ce que le modèle converge#
Les étapes 1 à 4 constituent ce que nous appelons un cycle unique d’apprentissage fédéré. Les paramètres du modèle global sont envoyés aux nœuds clients participants (étape 1), les nœuds clients s’entraînent sur leurs données locales (étape 2), ils envoient leurs modèles mis à jour au serveur (étape 3), et le serveur agrège ensuite les mises à jour du modèle pour obtenir une nouvelle version du modèle global (étape 4).
During a single round, each client node that participates in that iteration only trains for a little while. This means that after the aggregation step (step 4), we have a model that has been trained on all the data of all participating client nodes, but only for a little while. We then have to repeat this training process over and over again to eventually arrive at a fully trained model that performs well across the data of all client nodes.
Conclusion#
Félicitations, tu comprends maintenant les bases de l’apprentissage fédéré. Il y a bien sûr beaucoup plus à discuter, mais c’était l’apprentissage fédéré en quelques mots. Dans les parties suivantes de ce tutoriel, nous irons plus en détail. Les questions intéressantes comprennent : comment pouvons-nous sélectionner les meilleurs nœuds clients qui devraient participer au prochain tour ? Quelle est la meilleure façon d’agréger les mises à jour du modèle ? Comment pouvons-nous gérer les nœuds clients qui échouent (stragglers) ?
Évaluation fédérée#
Just like we can train a model on the decentralized data of different client nodes, we can also evaluate the model on that data to receive valuable metrics. This is called federated evaluation, sometimes abbreviated as FE. In fact, federated evaluation is an integral part of most federated learning systems.
Analyses fédérées#
Dans de nombreux cas, l’apprentissage automatique n’est pas nécessaire pour tirer de la valeur des données. L’analyse des données peut donner des indications précieuses, mais là encore, il n’y a souvent pas assez de données pour obtenir une réponse claire. Quel est l’âge moyen auquel les gens développent un certain type de problème de santé ? L’analyse fédérée permet de telles requêtes sur plusieurs nœuds clients. Elle est généralement utilisée en conjonction avec d’autres technologies de renforcement de la confidentialité, comme l’agrégation sécurisée, pour empêcher le serveur de voir les résultats soumis par les nœuds clients individuels.
Differential Privacy#
Differential privacy (DP) is often mentioned in the context of Federated Learning. It is a privacy-preserving method used when analyzing and sharing statistical data, ensuring the privacy of individual participants. DP achieves this by adding statistical noise to the model updates, ensuring any individual participants’ information cannot be distinguished or re-identified. This technique can be considered an optimization that provides a quantifiable privacy protection measure.
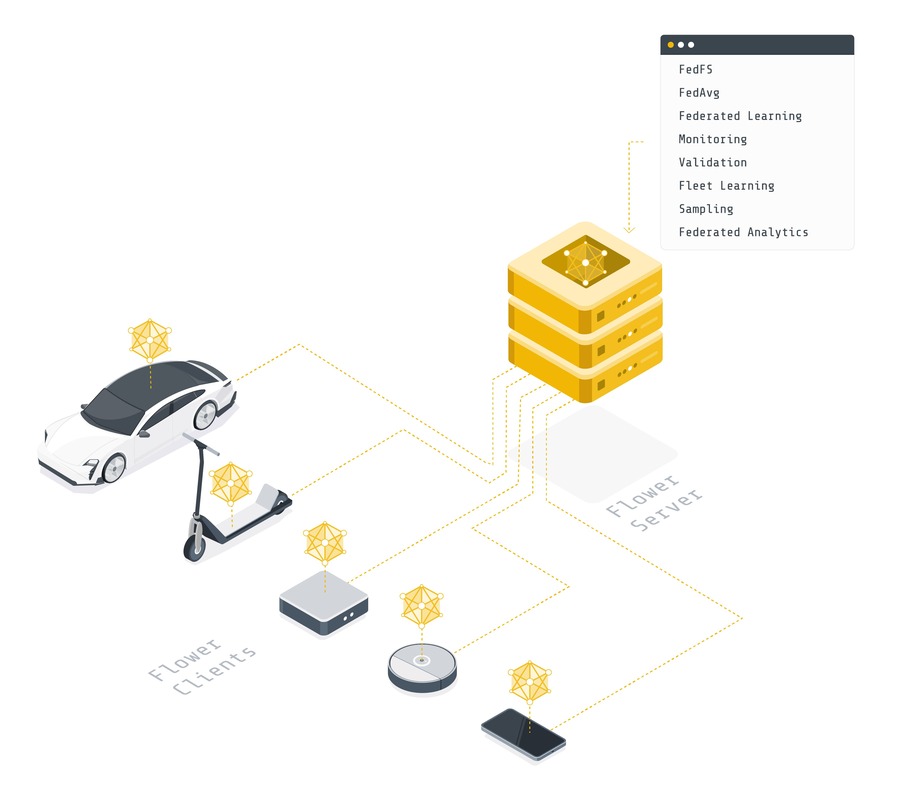
Fleur#
L’apprentissage fédéré, l’évaluation fédérée et l’analyse fédérée nécessitent une infrastructure pour déplacer les modèles d’apprentissage automatique dans les deux sens, les entraîner et les évaluer sur des données locales, puis agréger les modèles mis à jour. Flower fournit l’infrastructure pour faire exactement cela de manière simple, évolutive et sécurisée. En bref, Flower présente une approche unifiée de l’apprentissage, de l’analyse et de l’évaluation fédérés. Il permet à l’utilisateur de fédérer n’importe quelle charge de travail, n’importe quel cadre de ML et n’importe quel langage de programmation.
Remarques finales#
Félicitations, tu viens d’apprendre les bases de l’apprentissage fédéré et son rapport avec l’apprentissage automatique classique (centralisé) !
Dans la prochaine partie de ce tutoriel, nous allons construire un premier système d’apprentissage fédéré avec Flower.
Prochaines étapes#
Avant de continuer, n’oublie pas de rejoindre la communauté Flower sur Slack : Join Slack
Il existe un canal dédié aux questions si vous avez besoin d’aide, mais nous aimerions aussi savoir qui vous êtes dans #introductions !
The Flower Federated Learning Tutorial - Part 1 shows how to build a simple federated learning system with PyTorch and Flower.